Elastic net model selection
A canonical and highly practical application of this theory is hyperparameter optimization for the Elastic Net. In machine learning and statistics, selecting the correct regularization parameters is critical to balancing data fidelity, model sparsity, and numerical stability.
Traditional approaches rely on exhaustive grid searches or cross-validation over a discrete set of hyperparameter combinations \((\alpha, \lambda)\). This process is computationally expensive. By formulating the hyperparameter tuning as a multi-objective optimization problem over a regularization map [BS19], PyTorch-BSF allows for a continuous exploration of the model space, often reducing the computational cost by orders of magnitude (e.g., achieving speeds up to 2,000 times faster than exhaustive search for a 3-objective problem).
Unified Framework for Sparse Modeling
The Elastic Net example is part of a broader framework for generalized sparse modeling. Any optimization problem expressed as a convex combination of several strongly convex functions can be analyzed using this approach:
where \(f_m\) represent different aspects of the model, such as data fidelity (loss functions) or structural priors (regularization terms). By ensuring each \(f_m\) is strongly convex (e.g., by adding a small \(L_2\) penalty \(\frac{\epsilon}{2} \|\beta\|_2^2\)), the resulting solution map \(x^*(w)\) is guaranteed to be weakly simplicial [MHI21], allowing for high-quality approximation via Bézier simplices.
This unified framework extends far beyond the standard Elastic Net:
Generalized Linear Models (GLMs): The loss term can be any negative log-likelihood with a canonical link function (e.g., Logistic, Poisson, or Gamma regression).
Structural Regularization: Practitioners can incorporate structural priors like Group Lasso [YL06], Fused Lasso [TSR+05], or Smoothed Lasso to encode spatial or group relationships between features.
Transfer Learning and Covariate Shift: By using importance-weighted empirical risk as the loss function, the framework can handle scenarios where the training and test data distributions differ (covariate shift).
Robust Estimation: Replacing the standard squared error with robust loss functions like the Huber loss allows for model selection that is resilient to outliers.
Elastic Net Formulation
For the standard Elastic Net, the underlying multi-objective problem involves simultaneously minimizing three objectives over the model weights \(\beta \in \mathbb{R}^N\):
where \(n\) is the number of observations and \(\epsilon > 0\) is a small constant ensuring strong convexity. These correspond to the hyperparameter mapping \(w = (w_1, w_2, w_3)\) where:
By training the model on a sparse subset of weight vectors \(w\) and fitting a Bézier simplex, we obtain a continuous solution map \((x^*, f \circ x^*): \Delta^{M-1} \to G^*(f)\) that maps any weight \(w\) to the optimal weights \(\beta\) and the corresponding objective values.
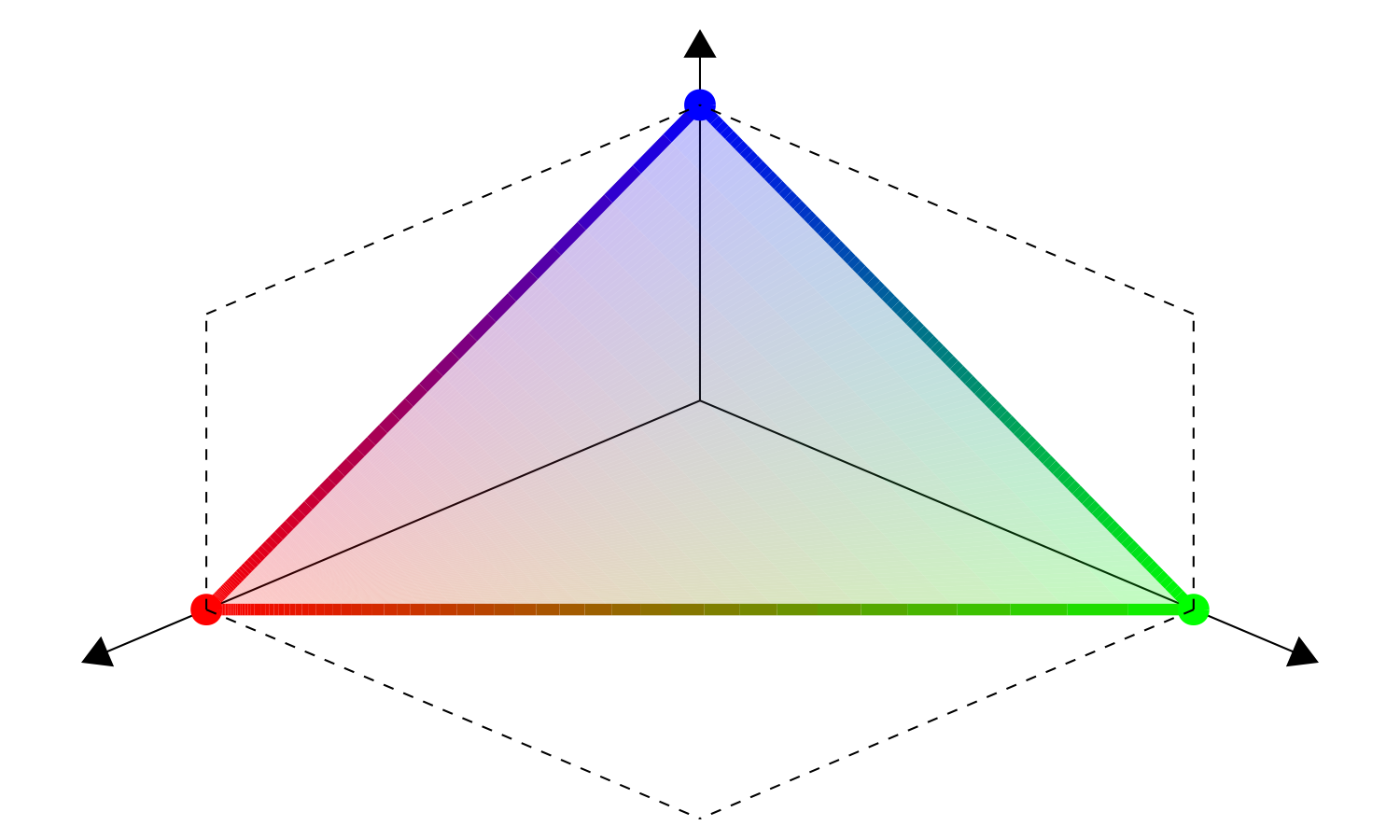
Fig. 6 Weight space \(\Delta^{2}\) |
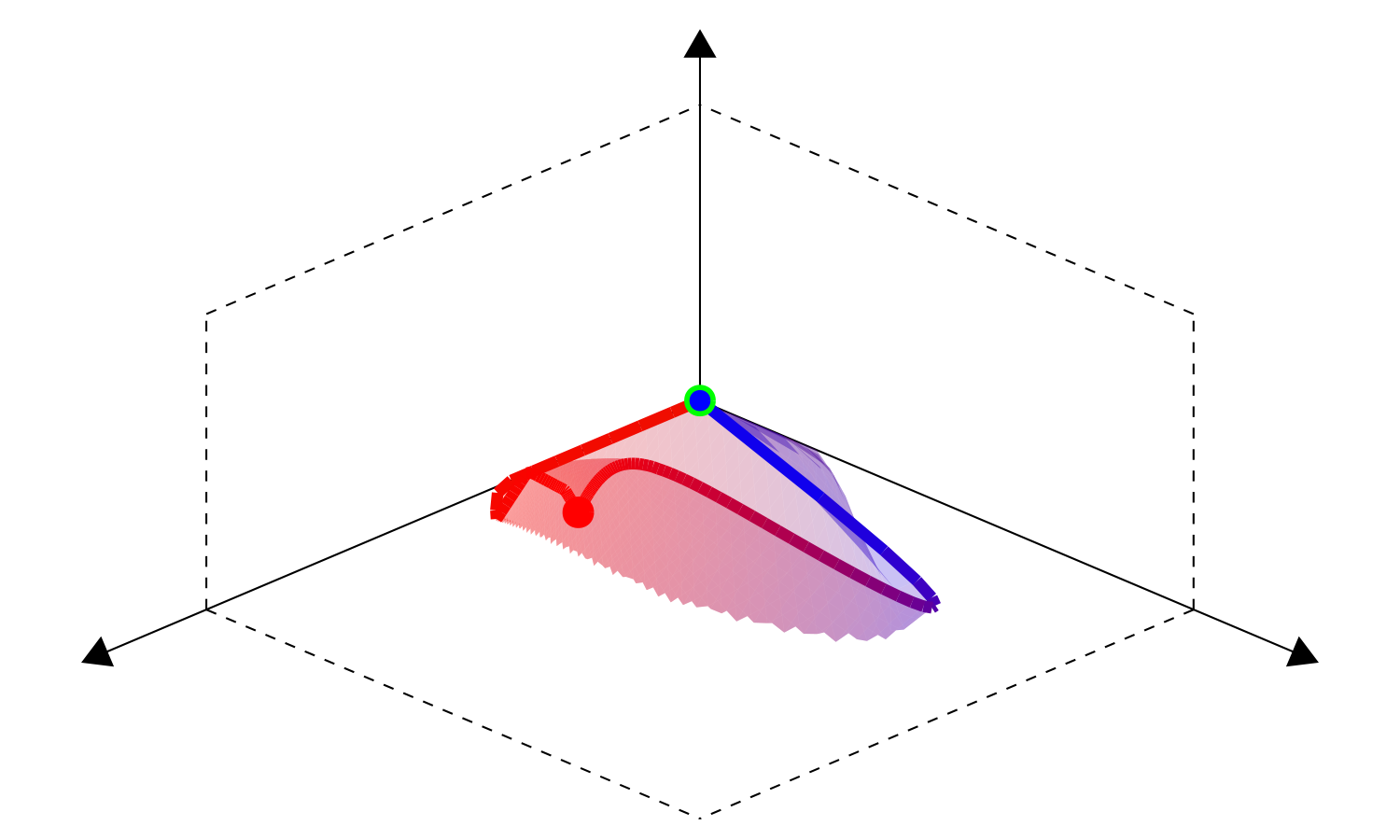
Fig. 7 Parameter space \(\Theta^*(f)\) |
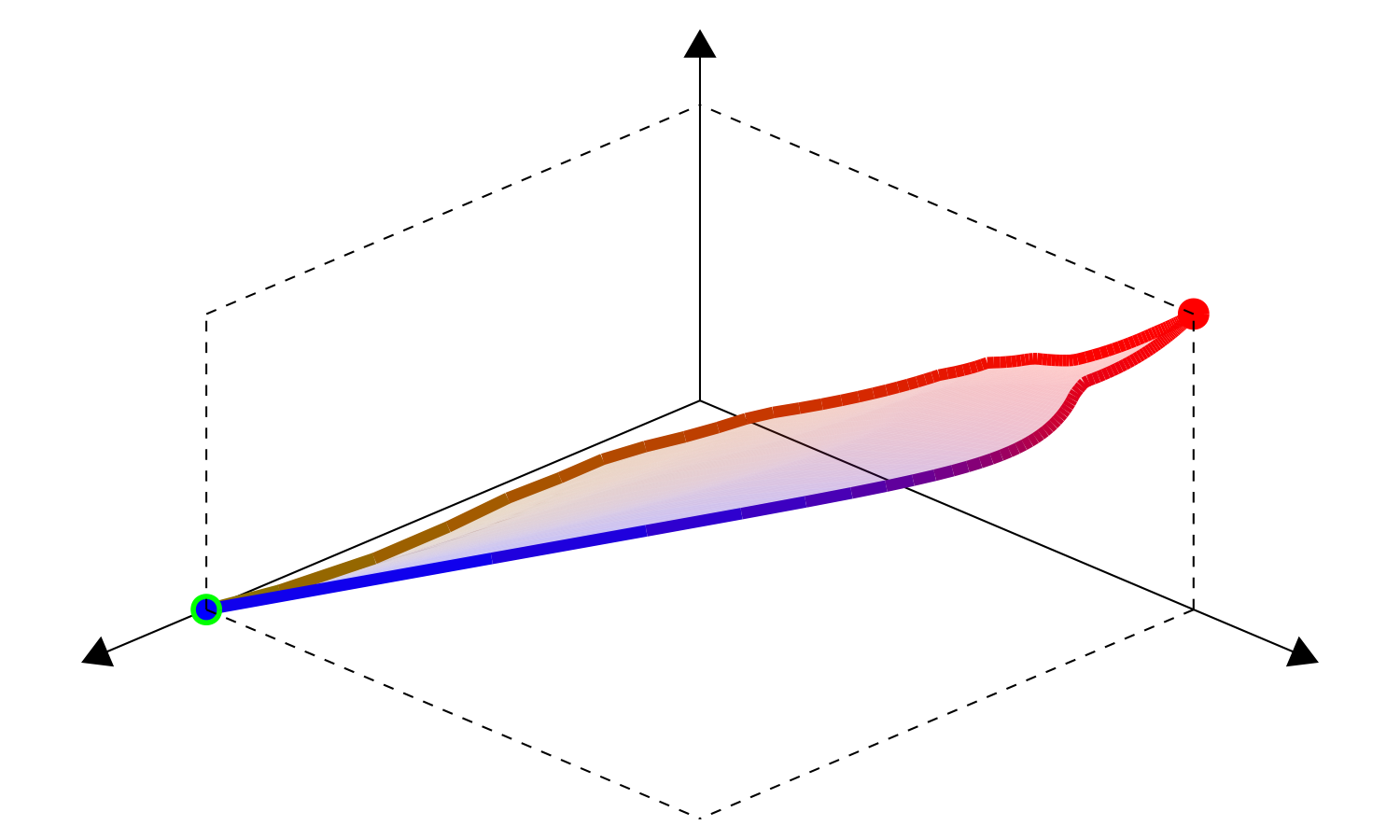
Fig. 8 Objective space \(f(\Theta^*(f))\) |
Model Selection on the Regularization Map
The resulting Bézier simplex provides a continuous surrogate of the performance surface, enabling users to apply various statistical model selection criteria analytically:
Minimum Cross-Validation Error (min profile rule): Locates the model \(w\) that minimizes the mean cross-validation error across folds, prioritizing predictive accuracy.
One Standard Error Rule (1se profile rule): Selects the most parsimonious (sparsest) model whose mean error is within one standard error of the minimum. This heuristic is widely used in tools like glmnet to gain stability and interpretability.
AICc Profile Rule: Balances goodness-of-fit and model complexity using the Akaike Information Criterion with Finite Sample Correction. This allows for selecting models with a theoretically grounded trade-off without the noise of fold-wise cross-validation variability.
Interactive Exploration and Insights
The Bézier simplex approximation of the regularization map provides more than just a tool for optimization. It offers a face structure that naturally reflects the combinations of subsets of loss and regularization terms. By observing the solutions on each face of the simplex, users can:
Obtain Insights: Gain a deep understanding of the trade-offs between different modeling assumptions, such as \(L_1\) vs \(L_2\) regularization.
Perform Exploratory Analysis: Test how sensitive the optimal model is to changes in hyperparameters without the trial-and-error of retraining.
Support Model Selection: Make better decisions a posteriori by seeing the entire landscape of potential models, rather than relying on a single fixed structure chosen a priori.
Empirical Evaluation
The effectiveness of PyTorch-BSF for Elastic Net is demonstrated using the Wine dataset from the UCI Machine Learning Repository. Experiments show that even with a limited number of training points (e.g., 51 points for a degree-6 simplex), the Bézier simplex accurately approximates the entire solution map, maintaining low Mean Squared Error (MSE) across the continuous hyperparameter space.
The following tables compare the results obtained through an exhaustive grid search (ground truth) and the Bézier simplex approximation. The high similarity between the performance surfaces confirms the fidelity of the surrogate model.
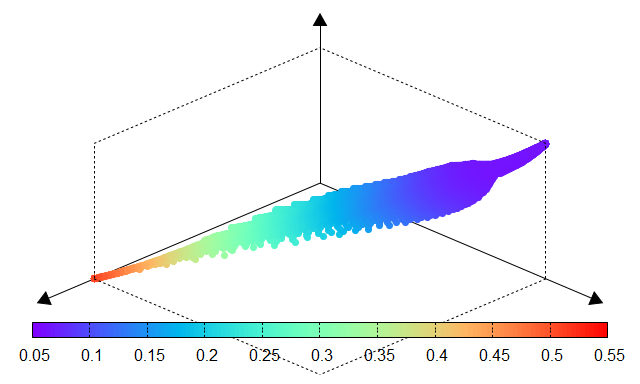
Fig. 9 Mean CV error |
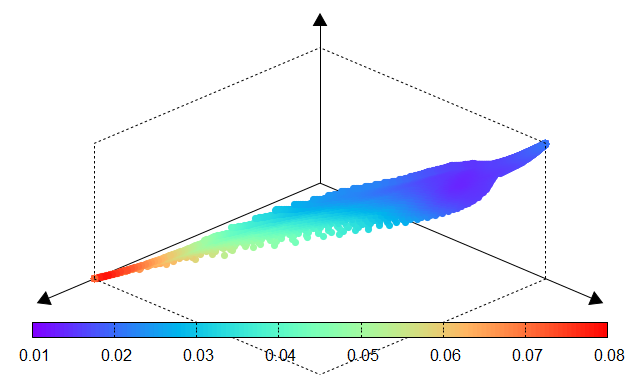
Fig. 10 Std dev of CV error |
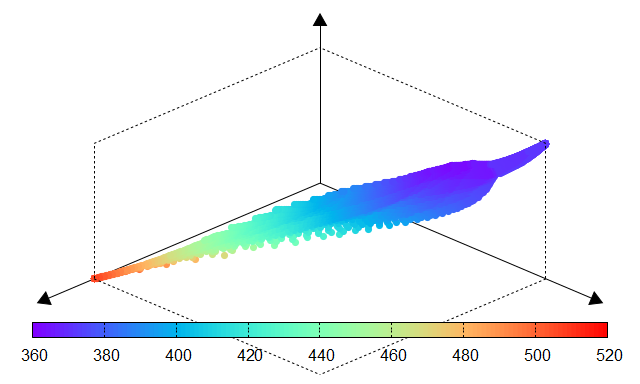
Fig. 11 AICc |
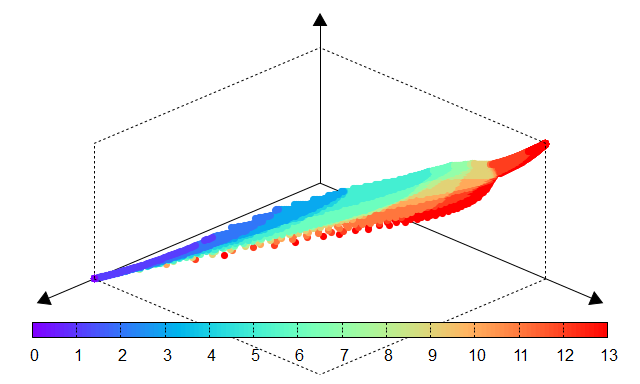
Fig. 12 Number of nonzero coefficients |

Fig. 13 Mean CV error |

Fig. 14 Std dev of CV error |

Fig. 15 AICc |

Fig. 16 Nonzero coefficients |
References
El Houcine Bergou, Youssef Diouane, and Vyacheslav Kungurtsev. Complexity iteration analysis for strongly convex multi-objective optimization using a newton path-following procedure. Optimization Letters, 15:1215–1227, 2021. doi:10.1007/s11590-020-01623-x.
Henri Bonnel and Corinne Schneider. Post-pareto analysis and a new algorithm for the optimal parameter tuning of the elastic net. Journal of Optimization Theory and Applications, 183(3):993–1027, 2019. doi:10.1007/s10957-019-01592-x.
S Breedveld, P Storchi, M Keijzer, A Heemink, and B Heijmen. A novel approach to multi-criteria inverse planning for imrt. Physics in Medicine and Biology, 2007.
Olivier de Weck and Il Yong Kim. Adaptive weighted sum method for multiobjective optimization. Submitted to Structural and Multidisciplinary Optimization for Review.
Jörg Fliege, L M Graña Drummond, and Benar Fux Svaiter. Newton's method for multiobjective optimization. SIAM Journal on Optimization, 20(2):602–626, 2009. doi:10.1137/08071692X.
Naoki Hamada. 多目的最適化の解集合のトポロジーの検定法 (statistical test for the topology of solution sets in multi-objective optimization). In 日本応用数理学会2020年度年会講演予稿集 (Proceedings of the JSIAM Annual Meeting 2020). 2020.
Naoki Hamada and Keisuke Goto. Data-driven analysis of pareto set topology. In Proceedings of the Genetic and Evolutionary Computation Conference, 657–664. 2018. URL: https://doi.org/10.1145/3205455.3205613.
Naoki Hamada, Kenta Hayano, Shunsuke Ichiki, Yutaro Kabata, and Hiroshi Teramoto. Topology of pareto sets of strongly convex problems. SIAM Journal on Optimization, 30(3):2659–2686, 2020. doi:10.1137/19M1264175.
Per Christian Hansen and Dianne Prost O'Leary. The use of the l-curve in the regularization of discrete ill-posed problems. SIAM Journal on Scientific Computing, 14(6):1487–1503, 1993. doi:10.1137/0914086.
Ken Kobayashi, Naoki Hamada, Akiyoshi Sannai, Aiko Tanaka, Kenichi Bannai, and Masashi Sugiyama. Bézier simplex fitting: describing pareto fronts of simplicial problems with small samples in multi-objective optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 2304–2313. 2019. URL: https://doi.org/10.1609/aaai.v33i01.33012304.
Suyun Liu and Luís N Vicente. The stochastic multi-gradient algorithm for multi-objective optimization and its application to supervised machine learning. Annals of Operations Research, 339(3):1119–1148, 2024. doi:10.1007/s10479-021-04033-z.
Harry Markowitz. Portfolio selection. The Journal of Finance, 7(1):77–91, 1952. doi:10.2307/2975974.
Yuto Mizota, Naoki Hamada, and Shunsuke Ichiki. All unconstrained strongly convex problems are weakly simplicial. 2021. URL: https://arxiv.org/abs/2106.12704, arXiv:2106.12704.
Houduo Qi. Optimal portfolio selections via l1,2-norm regularization. URL: https://eprints.soton.ac.uk/451606/1/mvpl12_for_PURE.pdf.
Robert Tibshirani, Michael Saunders, Saharon Rosset, Ji Zhu, and Keith Knight. Sparsity and smoothness via the fused lasso. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(1):91–108, 2005.
Dongxiang Yan, He Yin, Tao Li, and Chengbin Ma. A two-stage scheme for both power allocation and ev charging coordination in a grid tied pv-battery charging station. IEEE Transactions on Industrial Informatics, 2021. doi:10.1109/TII.2021.3054417.
Ming Yuan and Yi Lin. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1):49–67, 2006.